
Qwen Max
Qwen Max is Alibaba's proprietary flagship line — the only closed-source models in the entire Qwen ecosystem. Everything else Alibaba releases (up to 397 billion parameters) ships under Apache 2.0. The Max models don't. They're API-only, you can't download the weights, and you can't run them on your own hardware.
Two Max models matter right now. Qwen3.5-Max-Preview debuted on LMArena in March 2026, where it immediately ranked above GPT-5.4 and Claude 4.5 Opus on English prompts. It brings a completely new architecture — hybrid GatedDeltaNet attention, native multimodal input, 250K token vocabulary — but it isn't publicly available yet. Qwen3-Max-Thinking, the previous generation, is live on DashScope and third-party APIs today with test-time scaling that pushes its math and reasoning scores above every competitor. It costs roughly 10x less than GPT-5.2.
If you're looking to run powerful Qwen models on your own machine instead, skip this page entirely and head to Qwen 3.5 or our guide to running Qwen locally.
Which Qwen Max Should You Use?
The newest and most capable. Multimodal, native GatedDeltaNet architecture, 250K vocabulary. Ranked #10 on LMArena English (March 2026). Not available via API yet — arena testing only. When it goes stable, this will be the one to use.
The strongest Max model you can actually use today. 1T+ MoE, 262K context, test-time scaling that hits perfect scores on AIME 2025. Available on DashScope, OpenRouter, and Novita AI. $1.20 / $6.00 per million tokens.
Older models like Qwen2.5-Max (January 2025) still work but are effectively obsolete — limited to 32K context with weaker reasoning across the board.
In This Guide
Qwen3.5-Max-Preview: The New Flagship (March 2026)
On March 19, 2026, Alibaba submitted Qwen3.5-Max-Preview to LMArena under a blind alias. The model entered anonymous head-to-head voting against every other frontier system — and landed at rank #10 on the English leaderboard with a score of 1481, beating GPT-5.4, Claude Opus 4.5, Grok 4.1, and every other Chinese-developed model.
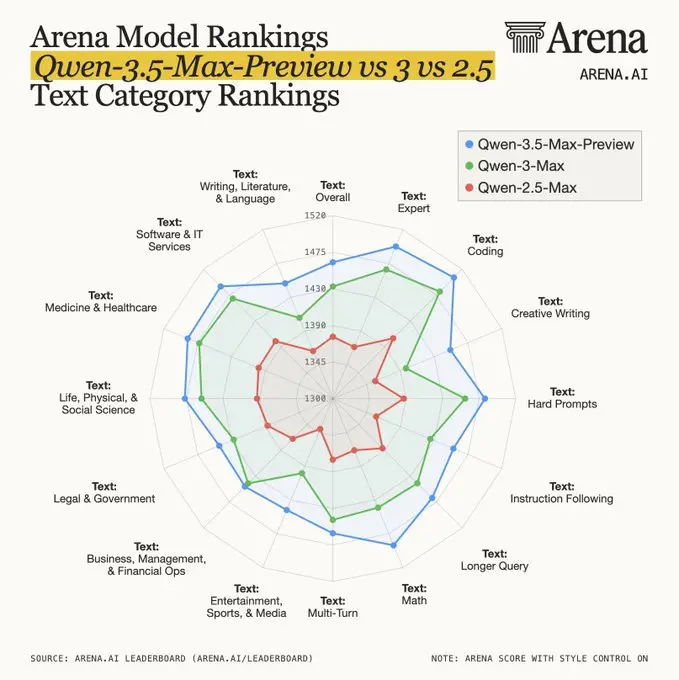
This is a generational leap, not an incremental update. The architecture is completely different from Qwen3-Max. Where the older model used standard attention, 3.5-Max-Preview runs a hybrid GatedDeltaNet + Sparse MoE design — 75% of its layers use linear attention that scales almost linearly with context length. That matters because standard transformer attention grows quadratically with sequence length, making long contexts expensive. GatedDeltaNet sidesteps that bottleneck entirely.
The vocabulary jumped from 152K to 250K tokens. Language coverage went from 119 to 201. And unlike Qwen3-Max (text-only), 3.5-Max-Preview processes text, images, and video natively — they're fused during pretraining, not bolted on afterward through adapter layers. Training happened in FP8 from the start, cutting activation memory roughly in half and enabling faster iteration on the same hardware budget.
What makes the LMArena result particularly noteworthy: the ranking placed Alibaba as the 5th best lab globally and first among Chinese AI companies. On expert-level prompts, the picture is even stronger — Qwen3.5-Max-Preview scored 1498 on LMArena Expert, also rank #10, with confidence intervals tightening as votes continue to accumulate.

Key Benchmarks (Self-Reported by Alibaba)
| Benchmark | Score | What It Measures |
|---|---|---|
| AIME 2026 | 91.3 | Math competition reasoning |
| GPQA Diamond | 88.4 | PhD-level science QA |
| LiveCodeBench v6 | 83.6 | Competitive coding |
| SWE-bench Verified | 76.4 | Real-world software engineering |
| MMLU-Pro | 87.8 | Broad knowledge |
| Tau2-Bench | 86.7 | Agentic tool use |
| MathVista | 90.3 | Math + vision |
| Video-MME | 87.5 | Video understanding |
The Tau2-Bench result deserves a closer look. At 86.7, Qwen3.5-Max-Preview trails only Claude Opus 4.6 (91.6) on agentic tasks — a category where the older Qwen3-Max scored just 82.1. That's a meaningful jump in real-world tool use, not just textbook benchmarks.
What's Different From Qwen3-Max?
| Aspect | Qwen3-Max | Qwen3.5-Max-Preview |
|---|---|---|
| Architecture | Standard attention + MoE | GatedDeltaNet (75% layers) + MoE |
| Vocabulary | 152K tokens | 250K tokens |
| Languages | 119 | 201 |
| Multimodal | Text only | Native (text + image + video) |
| Training precision | BF16/FP16 | FP8 native |
| Decoding speed | Baseline (~38 tok/s) | 8.6-19x faster (claimed) |
| Inference cost | Baseline | ~60% cheaper (claimed) |
The speed and cost claims are from Alibaba and haven't been independently verified. If they hold up — and the GatedDeltaNet architecture makes the speed gains plausible — Qwen3.5-Max would widen an already large cost advantage over GPT-5 and Claude. Even without those claims, the architectural shift alone represents the most substantial upgrade in the Max line's history.
One thing 3.5-Max-Preview shares with its predecessor: thinking mode is built in. You toggle it the same way (enable_thinking), but there's no separate "3.5-Max-Thinking" model — reasoning capability comes integrated from the start rather than being added months later as a separate upgrade.
When Can You Actually Use It?
Right now, you can't select Qwen3.5-Max-Preview anywhere. It's not on chat.qwen.ai, it's not on DashScope, and there's no API endpoint. Alibaba submitted it directly to LMArena for anonymous competitive testing — the same approach DeepSeek used with R1 and OpenAI used with GPT-5 (submitted as "summit") before their public launches.
The "Preview" label means Alibaba is iterating based on arena feedback before committing to a stable release. Based on history — Qwen3-Max went from preview in September 2025 to stable production within a couple of months — expect Qwen3.5-Max to reach API availability sometime in Q2 2026. No official date has been announced.
There's relevant context here: 3.5-Max-Preview launched during a turbulent period for the Qwen team. Four senior leaders departed in March 2026 amid an internal reorganization at Alibaba. The fact that the Preview shipped on schedule — and performed well enough to crack the LMArena top 10 — suggests the broader Qwen operation has enough depth to continue iterating. Whether the transition slows down the Preview-to-stable pipeline remains to be seen.
Qwen3-Max-Thinking: The Best Max You Can Use Today
Until 3.5-Max hits general availability, Qwen3-Max-Thinking is the strongest proprietary Qwen model you can actually build with. It's a 1+ trillion parameter MoE system with a 262K token context window, and its January 2026 upgrade added test-time scaling that pushes benchmark scores well above the base model.

Key Specs
| Parameters | 1+ trillion (Mixture-of-Experts) |
| Context Window | 262,144 tokens (256K) |
| Max Output | 32,768 tokens |
| Max Chain-of-Thought | 81,920 tokens |
| Languages | 119 |
| Output Speed | ~38-39 tokens/second |
| API Model ID | qwen3-max-2026-01-23 (alias: qwen3-max) |
| License | Proprietary — API-only |
Test-Time Scaling: Trading Compute for Accuracy
The "Thinking" in Qwen3-Max-Thinking isn't just a marketing label. When you set enable_thinking: true, the model activates what Alibaba calls an "experience-cumulative, multi-round reasoning strategy." In practice, that means the model doesn't generate one answer and stop. It revisits its reasoning across multiple internal passes, building on each attempt rather than starting from scratch. During this process, it can also invoke built-in tools — search, memory, and a code interpreter — to gather information or verify intermediate steps.
This is fundamentally different from naive best-of-N sampling, where you just generate multiple answers and pick the best one. Qwen3-Max-Thinking's approach is iterative and cumulative — each pass has access to the reasoning from previous passes. The tradeoff is latency. Thinking mode is significantly slower. But for hard problems, the accuracy gains are substantial:
| Benchmark | Standard | With TTS | Gain |
|---|---|---|---|
| AIME 2025 | 81.6 | 100.0 | +18.4 |
| GPQA Diamond | 87.4 | 92.8 | +5.4 |
| LiveCodeBench v6 | 85.9 | 91.4 | +5.5 |
| IMO-AnswerBench | 83.9 | 91.5 | +7.6 |
| HLE (with search) | 49.8 | 58.3 | +8.5 |
A perfect 100 on AIME 2025 is the headline number, but the +8.5 jump on HLE with search is arguably more meaningful — that's a test designed to stump frontier models.
You control when to use it. Set enable_thinking: false for fast chat, customer support, or simple queries where latency matters more than depth. Flip it to true for math olympiad problems, complex STEM reasoning, or agentic workflows where accuracy is everything.
Pricing: The Real Competitive Advantage
| Provider | Input / 1M tokens | Output / 1M tokens |
|---|---|---|
| DashScope (up to 128K) | $1.20 | $6.00 |
| DashScope (over 128K) | $3.00 | $15.00 |
| Novita AI | $0.50 | $5.00 |
| OpenRouter | $0.78 | $3.90 |
Compare that to GPT-5.2 at $15/$60 or Claude Opus at $15/$75 per million tokens. Qwen3-Max-Thinking is 10-12x cheaper for benchmark performance that matches or beats both on math, science, and coding tasks. On Novita AI, you can run it for roughly $0.50 input — that's budget territory for a frontier-class model. If you're building an API-heavy product and cost matters (when doesn't it?), this pricing gap is hard to ignore.
API Quick Start (Python)
from openai import OpenAI
client = OpenAI(
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
api_key="your-dashscope-api-key"
)
response = client.chat.completions.create(
model="qwen3-max-2026-01-23",
messages=[{"role": "user", "content": "Prove that sqrt(2) is irrational."}],
extra_body={"enable_thinking": True}
)
print(response.choices[0].message.content)
The endpoint is OpenAI-compatible, so any SDK or tool that works with OpenAI's API works here with just a base URL swap. Qwen3-Max-Thinking is also accessible on OpenRouter (as qwen/qwen3-max-thinking), DeepInfra, and Novita AI. For a free trial, you can use it directly at chat.qwen.ai — look under "deploy more models."
A practical note on dual-mode usage: you don't need two separate deployments. The same API endpoint handles both modes. Route your simple queries with enable_thinking: false for fast responses and your hard problems with enable_thinking: true for deep reasoning. The model ID stays the same. This makes it straightforward to build routing logic that sends easy customer support questions through fast mode and complex STEM queries through thinking mode — one API key, one integration, two performance profiles.
Benchmarks Compared: Every Max vs the Competition
Here's the full picture with both Max generations side by side against GPT-5.2, Claude Opus 4.5, and Gemini 3 Pro. Qwen3.5-Max-Preview benchmarks are self-reported by Alibaba and reflect the model's current Preview state; Qwen3-Max-Thinking scores use test-time scaling at full depth. Competitor numbers come from their respective official reports.
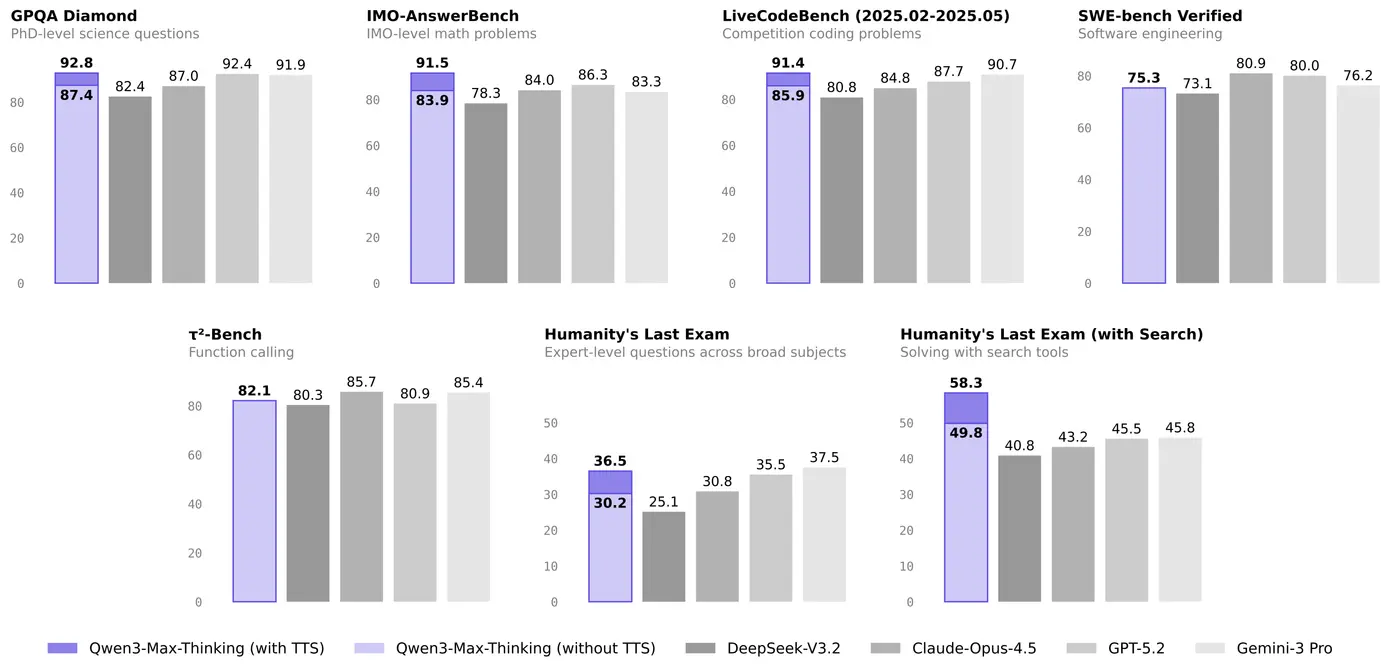
| Benchmark | 3.5-Max-Preview | 3-Max-Thinking | GPT-5.2 | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|---|---|
| GPQA Diamond | 88.4 | 92.8 | 92.4 | 87.0 | 91.9 |
| MMLU-Pro | 87.8 | 85.7 | — | — | — |
| LiveCodeBench v6 | 83.6 | 91.4 | 87.7 | 84.8 | 90.7 |
| SWE-bench Verified | 76.4 | 75.3 | 80.0 | 80.9 | 76.2 |
| HLE (with search) | — | 58.3 | 45.5 | 43.2 | 45.0 |
| IMO-AnswerBench | — | 91.5 | 86.3 | 84.0 | 83.3 |
| Tau2-Bench | 86.7 | 82.1 | 80.9 | 85.7 | 85.4 |
| IFBench | 76.5 | 70.9 | — | — | — |
Bold = highest score in row. Dashes indicate scores not reported on that benchmark. All Qwen scores are self-reported by Alibaba.
The pattern is clear. Qwen3-Max-Thinking dominates pure math and reasoning (GPQA, IMO, HLE with search). Claude Opus 4.5 wins on real-world software engineering (SWE-bench) and agentic tasks (Tau2-Bench). GPT-5.2 sits in between. And Qwen3.5-Max-Preview, even in its unfinished state, already shows improvements on knowledge (MMLU-Pro), instruction following (IFBench), and agentic tasks over its predecessor.
A few things jump out from this table. First, Qwen3-Max-Thinking with TTS still leads its successor on several benchmarks — particularly GPQA Diamond (92.8 vs 88.4) and LiveCodeBench (91.4 vs 83.6). This likely reflects the fact that 3.5-Max-Preview numbers don't use the full TTS pipeline yet, or that the Preview version hasn't been fully optimized. Second, the real competitive gap for both Max models is SWE-bench — Claude Opus 4.5's 80.9 is a meaningful lead on real-world software engineering tasks.
A necessary caveat: all Qwen benchmark numbers come from Alibaba's own reports. Independent verification sometimes tells a different story — AI researcher Nathan Lambert has observed that Qwen consistently produces "legitimately fantastic models" that also "happen to have insane benchmark scores." The models are genuinely strong, but take self-reported numbers with appropriate skepticism. The LMArena rankings provide independent confirmation of general quality, even if specific benchmark claims are harder to verify.
Where the Max Models Shine — and Where They Fall Short
Genuine Strengths
Honest Gaps
- Software engineering (SWE-bench: 75.3-76.4): Both Max models trail Claude Opus 4.5 (80.9) and GPT-5.2 (80.0) on real-world multi-file debugging. Competitive coding scores don't translate directly to production codebases. For serious coding work, Qwen Coder is the better specialized pick.
- Speed: Qwen3-Max-Thinking outputs roughly 38 tokens per second — slower than most frontier competitors. Enable thinking mode and latency climbs further. This isn't the model for latency-sensitive chatbots.
- Agent reliability: Tau2-Bench at 82.1 (Qwen3-Max-Thinking) is decent but not best-in-class. Claude and Gemini handle complex multi-step tool chains more consistently right now. The 3.5-Max-Preview score of 86.7 narrows that gap significantly.
- No local option: You can't self-host any Max model. Period. If vendor independence matters, Qwen 3.5's open-source 397B MoE is the closest alternative — and it's surprisingly competitive. Check our hardware compatibility tool to see what fits your setup.
When to Reach for Qwen Max
When not to use Max: For general coding and daily development tasks, Qwen Coder is purpose-built and faster. For simple chat or Q&A where you don't need frontier reasoning, Qwen Plus is cheaper and responds faster. And for anything requiring on-premise deployment, data sovereignty, or fine-tuning — Max simply isn't an option.
What about running locally? The Max models aren't available for self-hosting. But Qwen's open-source lineup covers more use cases than most people realize. The Qwen 3.5 397B-A17B activates only 17 billion parameters per token while matching or beating many closed competitors on practical tasks. For a full walkthrough, see our guide to running Qwen on your own hardware, or use our hardware compatibility checker to find which model fits your GPU.
Qwen Max Timeline
| January 2025 | Qwen2.5-Max launched — 32K context, API-only. Now largely obsolete. |
| September 5, 2025 | Qwen3-Max launched — 1T+ MoE, 262K context window, major leap over 2.5-Max. |
| November 2025 | Thinking mode added to Qwen3-Max (early version without full TTS). |
| January 27, 2026 | Qwen3-Max-Thinking with test-time scaling — perfect AIME 2025, #1 on HLE with search. |
| February 16, 2026 | Qwen 3.5 open-source released (397B MoE). Sets the stage for a 3.5-Max model. |
| March 19, 2026 | Qwen3.5-Max-Preview debuts on LMArena — rank #10 English, beats GPT-5.4 and Claude 4.5 Opus. |
| Expected Q2 2026 | Qwen3.5-Max stable release + public API (unconfirmed — extrapolated from Qwen3-Max's ~2-3 month preview-to-production cycle). |
Frequently Asked Questions
Is Qwen Max open source?
No — and it's the exception, not the rule. The Max line is the only proprietary part of the Qwen ecosystem. Every other Qwen model — from the 0.6B nano model to the 397B-parameter Qwen 3.5, plus Coder, ASR, TTS, and more — ships under Apache 2.0 with full weights available. This is genuinely unusual in the industry. Most AI companies keep their best models locked down. Alibaba keeps everything open except Max.
Can I run Qwen Max on my own hardware?
No. The weights aren't public and never have been. For the most capable self-hosted option, look at Qwen3.5-397B-A17B — it's open-source under Apache 2.0, uses Mixture-of-Experts to activate only 17B parameters per token, and scores competitively with several closed frontier models. Our Can I Run Qwen? tool shows exactly what fits your GPU.
What's the difference between Max, Max-Thinking, and Max-Preview?
Qwen3-Max is the base model from September 2025. Qwen3-Max-Thinking is the same model with test-time scaling enabled (January 2026 upgrade) — you toggle it via enable_thinking in the API. Qwen3.5-Max-Preview is a completely new generation with a different architecture, currently in arena testing only.
When will Qwen3.5-Max be available via API?
No official date. Going by precedent — Qwen3-Max took about 2-3 months from preview to production API — a reasonable guess is Q2 2026. Alibaba hasn't committed to anything publicly.
Should I wait for 3.5-Max or use 3-Max-Thinking now?
If you need API access today, don't wait. Qwen3-Max-Thinking is genuinely excellent for math, reasoning, and research tasks, and it costs a fraction of what you'd pay for GPT-5.2. When 3.5-Max goes live, it'll likely be better across the board — multimodal input, faster decoding, cheaper inference, and improved agentic performance. But "Preview" means weeks to months of waiting with no guaranteed date. Don't stall a product roadmap on a model that's still in anonymous arena testing.
How does pricing compare to GPT-5 and Claude?
Qwen3-Max-Thinking on DashScope: $1.20 input / $6.00 output per million tokens. GPT-5.2: $15/$60. Claude Opus: $15/$75. That's roughly 10-12x cheaper. Even on the highest-priced tier (over 128K context), Qwen3-Max still undercuts competitors by 5x or more. Through Novita AI or OpenRouter, rates drop even further.
Limitations You Should Know
- Closed source and vendor-locked: You're dependent on Alibaba Cloud's infrastructure, uptime, and pricing decisions. No weights, no fine-tuning, no self-hosting. If that's a dealbreaker, Qwen 3.5 open-source is the alternative.
- Qwen3-Max-Thinking is text-only: No image, audio, or video input. Qwen3.5-Max-Preview will add multimodal capabilities, but it's not available yet.
- Slower than most frontier models: ~38 tokens/second for Qwen3-Max-Thinking. Thinking mode adds further latency. Don't use this for real-time chat applications where speed matters more than depth.
- Real-world coding trails the leaders: SWE-bench scores of 75-76 put both Max models behind Claude Opus 4.5 and GPT-5.2 for practical software engineering. Benchmark coding and production coding are different skills.
- Self-reported benchmarks: All numbers for both Max models come from Alibaba. Independent testing on LMArena confirms the models are legitimately strong, but specific benchmark figures should be taken as directional rather than absolute.
- 3.5-Max-Preview availability is uncertain: There's no public timeline for API access. Planning a product around a model still in anonymous arena testing carries real risk.
- Context window pricing jump: DashScope charges $1.20/$6.00 for prompts under 128K tokens, but that jumps to $3.00/$15.00 for longer contexts. If your use case involves long documents, the cost advantage over competitors shrinks considerably at the higher tier.