
Qwen Coder
Qwen Coder is Alibaba's family of code-specialized AI models — and right now, it's one of the most interesting lineups in open-source coding. The family has three models: Qwen3-Coder-Next (the efficiency star, 70.6% SWE-Bench with only 3B active parameters), Qwen3-Coder 480B (the heavyweight API model), and Qwen3-Coder 30B (the budget pick). On top of that, there's Qwen Code, a free open-source CLI agent with 18K GitHub stars that ties them all together.
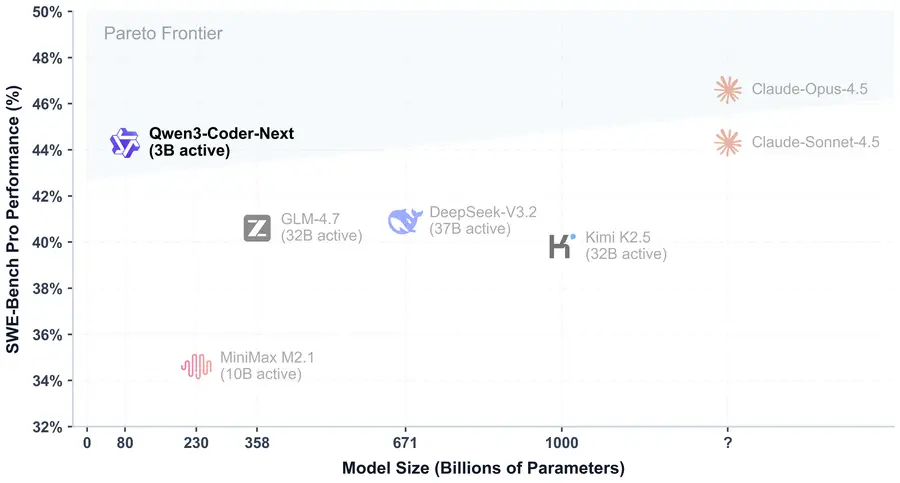
The headline story here is Coder-Next. Released February 2026, it matches roughly Claude Sonnet 4.0-level coding performance while activating just 3 billion parameters per token out of 80B total. That efficiency gap isn't incremental — it's 10-20x less compute than comparable dense models. If you've been waiting for a local coding agent that doesn't require a datacenter, this is the one to watch.
This guide covers every model in the family: specs, real benchmarks (with honest caveats), API pricing, local setup, the Qwen Code CLI, and what the community actually thinks after weeks of daily use.
In This Guide
Qwen3-Coder-Next: The Efficiency Champion
Released February 3, 2026, Qwen3-Coder-Next is the model that put Qwen on the coding agent map for local users. The pitch is simple: frontier-level coding with 3B active parameters. That's not a typo. The model has 80B total parameters spread across 512 experts, but each token only activates 10 experts plus 1 shared — totaling about 3B active compute per forward pass.
Why does that matter? Speed. On consumer hardware with 64GB RAM, community testers report 60-70 tokens per second with 5-bit quantization. Some have run six parallel inference windows hitting 150 tok/s combined. That's the kind of throughput that makes agentic coding loops — write, test, fix, repeat — actually practical on a single machine.
| Release Date | February 3, 2026 |
| Total / Active Params | 80B total, 3B active per token |
| Architecture | Hybrid MoE — Gated DeltaNet + Gated Attention (48 layers) |
| Experts | 512 total, 10 active + 1 shared per token |
| Context Window | 256K tokens native, ~1M with YaRN scaling |
| Max Output | 65,536 tokens |
| Thinking Mode | Non-thinking only (fast, no chain-of-thought blocks) |
| License | Apache 2.0 — fully open, commercial use allowed |
| Key Strength | Agentic coding: write, execute, debug, fix autonomously |
How the Architecture Works (Brief)
Each of the 48 layers alternates between two attention types: Gated DeltaNet (a linear attention variant optimized for long sequences) and Gated Attention (traditional multi-head attention for precise token-level patterns). The pattern repeats as 3 DeltaNet layers followed by 1 Gated Attention layer, each feeding into a MoE routing block.
The practical upside: context length scales to 256K tokens without the VRAM explosion you'd get from a standard dense transformer. Running a 4-bit quant at 65K context fits comfortably in consumer memory budgets. For the full architecture of the base model this was built on, see our Qwen3-Next overview.
From Autocomplete to Autonomous Agent
Coder-Next wasn't trained like a typical code model. Alibaba used what they call "agentic training signals" — the model was placed in containerized environments with over 800,000 executable tasks and trained through reinforcement learning from environment feedback. It would write code, run it, observe failures, and learn to self-correct. Not from static examples. From actual execution.
The result is a model that doesn't just suggest code — it can open a terminal, run tests, read error output, identify the bug, write a fix, and verify it passes. Community testers have shown it resolving real open-source bugs end-to-end in under a minute. It integrates with Claude Code, Cline, Kilo, Trae, OpenCode, Continue.dev, and of course Alibaba's own Qwen Code CLI.
What People Have Actually Built With It
Independent testers have pushed Coder-Next hard since launch — and the results are genuinely impressive for a model you can run locally. A few highlights:
- Browser-based OS clone — A MacOS-style interface generated in a single HTML file, complete with working calculator, image gallery, wallpaper customization, and a real-time audio visualizer using the Web Audio API. Testers called it one of the most feature-complete single-shot generations they'd seen from any model.
- 3D racing game — Highway racing with vehicle physics (lean on turns), collision effects, multiple car models, and smooth death transitions. Reviewers rated it better than equivalent outputs from Claude in similar side-by-side tests.
- Production-quality SQL optimization — Correctly identified three major performance issues (non-sargable predicates, correlated subqueries) and provided two optimization approaches with indexing recommendations. Experienced database engineers described the output as production-ready.
A consistent pattern across all demos: Coder-Next excels at iterative self-correction. Feed it error output from a browser console or test runner, and it identifies the problem and produces a corrected version — often dramatically improving on the second or third attempt. That's the agentic training showing through. The model doesn't just generate code; it debugs code, and that's the harder skill.
IDE and Tool Integration
Coder-Next supports native tool calling as a first-class feature. It can invoke external tools through structured function calls — reading files, running tests, analyzing output, applying fixes — all in an automated loop. Both vLLM and SGLang expose the dedicated qwen3_coder tool-call parser for seamless integration with agentic frameworks.
The model works with practically every major coding agent platform: OpenCode, Cline (VS Code), Kilo, Trae, Continue.dev, and Twinny. It also powers browser automation workflows — navigating web apps, filling forms, extracting data. If you've used Qwen 3.5 for general tasks and wanted something code-focused, Coder-Next is the specialized answer.
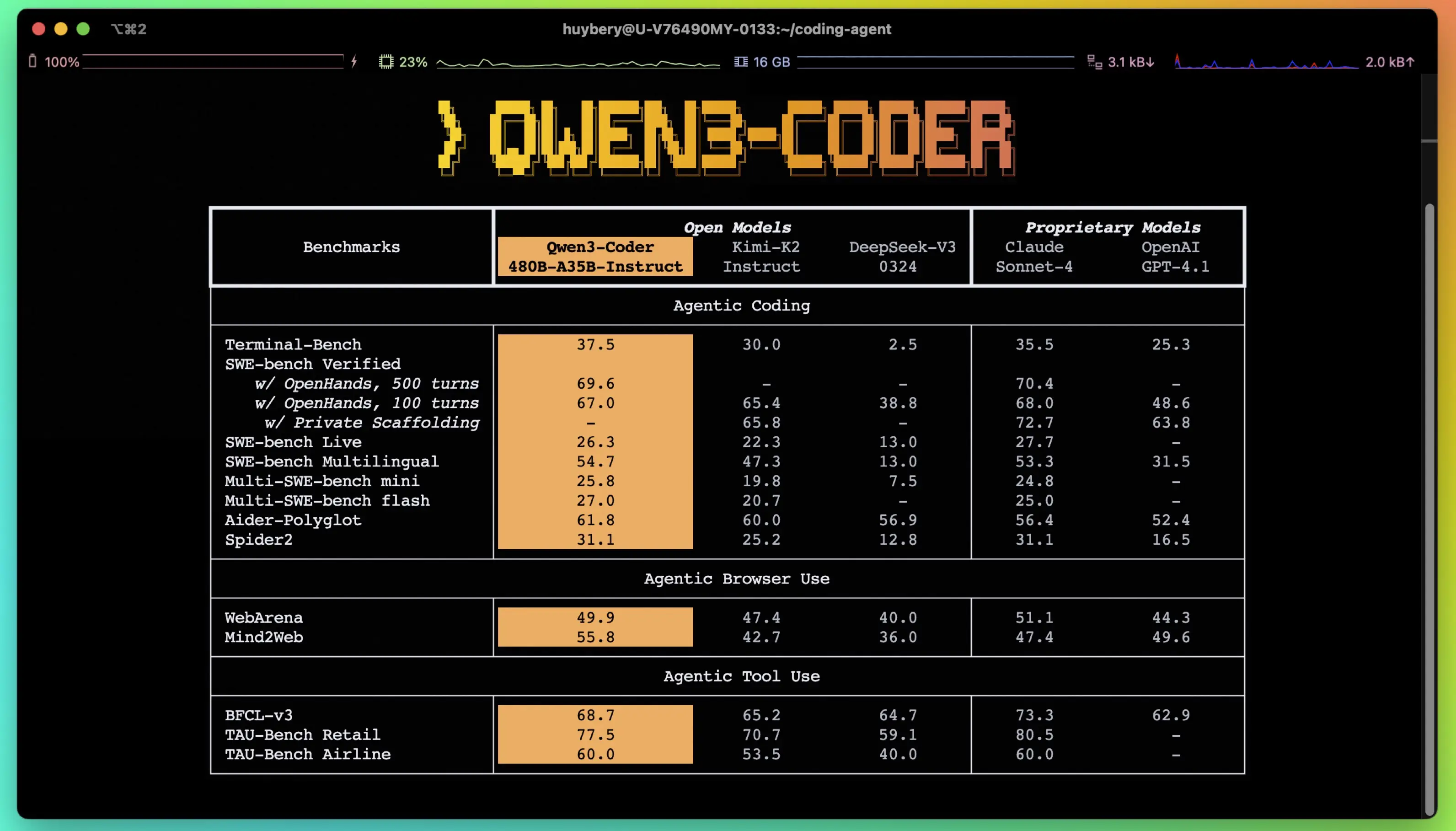
Benchmarks: Where Coder-Next Wins (and Where It Doesn't)
Here's the raw data. Coder-Next competes with models that have 10-20x more active parameters, which is genuinely remarkable. But it doesn't win everywhere — and you should know where the gaps are before committing to it.
| Benchmark | Coder-Next (3B active) | DeepSeek-V3.2 | GLM-4.7 |
|---|---|---|---|
| SWE-Bench Verified | 70.6% | 70.2% | 74.2% |
| SWE-Bench Pro | 44.3% | 40.9% | 40.6% |
| SWE-Bench Multilingual | 62.8% | — | — |
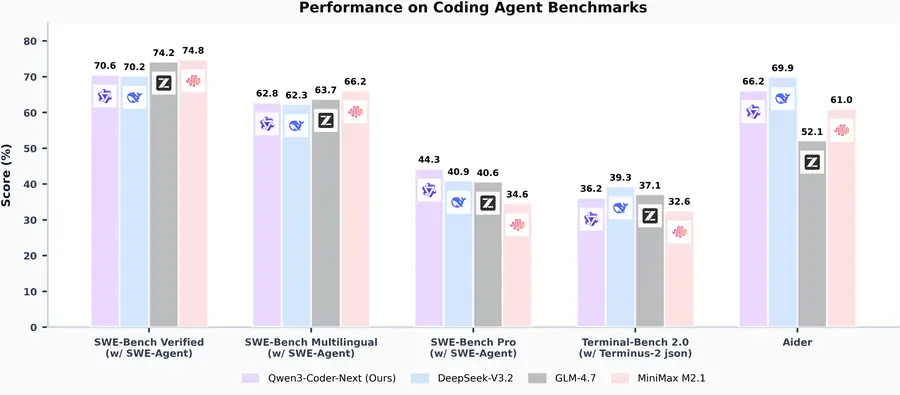
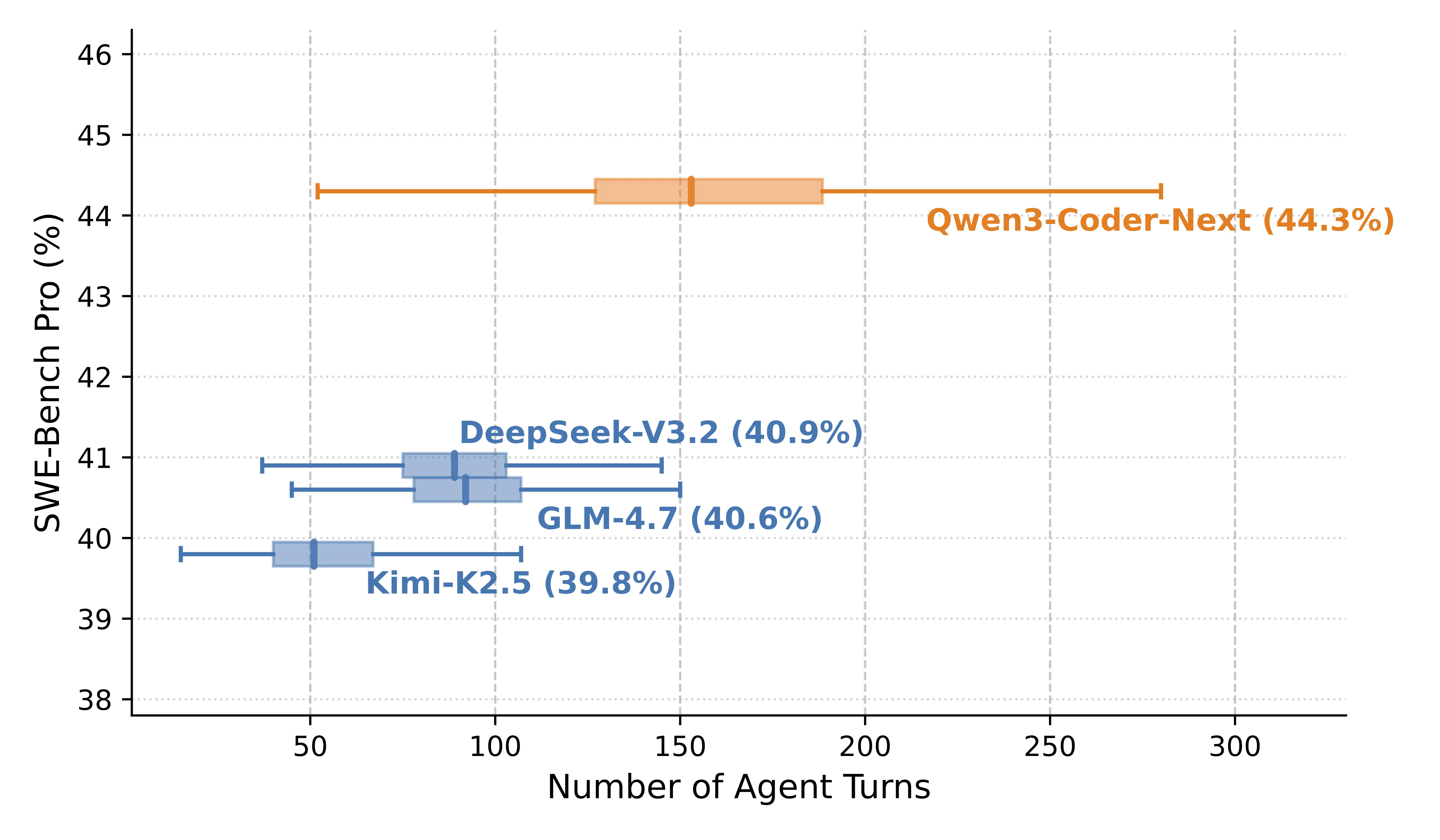
On SWE-Bench Verified — the standard test for autonomous bug-fixing across real repositories — Coder-Next hits 70.6%. That edges out DeepSeek-V3.2 (70.2%) and puts it in the same league as models with vastly more compute. On SWE-Bench Pro, a harder variant with more complex tasks, it leads with 44.3% versus DeepSeek's 40.9% and GLM's 40.6%.
The honest caveat: GLM-4.7 beats Coder-Next on standard SWE-Bench Verified (74.2% vs 70.6%). And Claude Opus 4.5 still sits well above all of these models on the hardest coding tasks. Coder-Next's claim isn't "best coding model, period" — it's "best coding model per unit of compute, by a wide margin." Sebastian Raschka's assessment puts it "roughly on par with Claude Sonnet 4.5" on SWE-Bench Pro, which is impressive given the 3B active parameters, but the comparison has limits on the most complex novel problems.
Running Coder-Next on Your Own Hardware
The MoE architecture makes this model far more accessible than its 80B parameter count suggests. The key metric isn't GPU VRAM alone — it's total system memory (RAM + VRAM combined). Most users run the GGUF quantizations through llama.cpp, Ollama, or LM Studio. Want to check if your specific setup can handle it? Use our Can I Run Qwen? tool.
Hardware Requirements by Setup
| Setup | Quantization | Memory Needed | Expected Speed |
|---|---|---|---|
| Consumer PC (64GB RAM) | Q5_K_M (5-bit) | ~57GB combined | ~60-70 t/s |
| Workstation (128GB RAM) | Q8_0 (8-bit) | ~85GB combined | ~60+ t/s |
| GPU server (H100 80GB) | FP8 | ~48-80GB VRAM | Very fast |
| Multi-GPU (2x A100/H100) | BF16 full | Distributed | Production-grade |
The sweet spot for most people: Q5_K_M quantization on a 64GB system. Community testers confirm 95% token accuracy at this level, and it fits comfortably in memory even at 65K context. Going below Q4 noticeably degrades output quality — don't bother with Q3 or lower.
GGUF Quantization Options
The GGUF format (for llama.cpp, Ollama, LM Studio) is the most popular choice for local deployment. Here's what each level costs you in disk/memory:
| Quantization | Size | Quality Notes |
|---|---|---|
| Q4_K_M (4-bit) | ~48GB | Minimum viable — noticeable quality loss on complex tasks |
| Q5_K_M (5-bit) | ~57GB | Recommended — 95% token accuracy, best size/quality balance |
| Q6_K (6-bit) | ~66GB | Higher quality, needs 64GB+ systems |
| Q8_0 (8-bit) | ~85GB | Near-lossless — requires 128GB systems |
Quick Start Commands
Ollama (easiest):
ollama run qwen3-coder-nextllama.cpp (most control):
huggingface-cli download Qwen/Qwen3-Coder-Next-GGUF --include "Qwen3-Coder-Next-Q5_K_M/*"./llama-cli -m ./Qwen3-Coder-Next-Q5_K_M/Qwen3-Coder-Next-00001-of-00004.gguf --jinja -ngl 99 -fa on -sm row --temp 1.0 --top-k 40 --top-p 0.95 -c 40960 -n 32768 --no-context-shiftvLLM (production server with tool calling):
vllm serve Qwen/Qwen3-Coder-Next --port 8000 --tensor-parallel-size 2 --enable-auto-tool-choice --tool-call-parser qwen3_coderLM Studio users: search for "Qwen3-Coder-Next" in the model browser, pick Q5 for 64GB systems or Q8 for 128GB+. Set temperature to 1.0, top_p to 0.95, top_k to 40 — these are the Qwen team's recommended sampling parameters across all backends.
For a complete walkthrough covering all deployment options, see our guide to running Qwen locally.
The Rest of the Family: Coder 480B and Coder 30B
Coder-Next is the newest and most efficient model, but the older siblings still have their roles. Here's the quick breakdown.
Qwen3-Coder-480B-A35B (July 2025)
The heavyweight. 480B total parameters, 35B active per token, 256K context (extendable to 1M via YaRN). This was the model that first put Qwen on the agentic coding leaderboard, scoring 67.0-69.6% on SWE-Bench Verified depending on the configuration.
You can't run this locally — it's an API-only model for most users. The sweet spot for 480B is when you need maximum quality and aren't worried about cost, since it's accessible via the DashScope API as qwen3-coder-plus. For a general-purpose comparison of all Qwen 3 models, see our family overview.
Qwen3-Coder-30B-A3B (July 2025)
The budget option. Same 3B active parameter count as Coder-Next, but with an older transformer architecture (no DeltaNet hybrid) and significantly lower benchmarks (~50.3% SWE-Bench Verified). If Coder-Next exists, why use this? Honestly, for most people, there isn't a strong reason anymore. It was the best efficient coder before February 2026; Coder-Next does everything it does but better, with the same memory footprint.
The one edge case: if you're running on extremely constrained hardware or need an architecture that's more widely supported by older inference engines, the 30B's simpler transformer design might have fewer compatibility issues. But that's a narrow use case. For the vast majority of developers, Coder-Next is the clear upgrade.
| Model | Active Params | SWE-Bench Verified | Best Use Case |
|---|---|---|---|
| Coder-Next (80B) | 3B | 70.6% | Local agents, self-hosted, best efficiency |
| Coder 480B | 35B | 67.0-69.6% | Cloud API, max quality when cost isn't an issue |
| Coder 30B | 3B | ~50.3% | Legacy — Coder-Next supersedes for most uses |
API Pricing: What It Costs to Use Qwen Coder
One of Qwen Coder's strongest selling points is price. Compared to Claude, GPT, or even DeepSeek's API models, the cost per million tokens is dramatically lower — especially for Coder-Next through OpenRouter.
| Model / Provider | Input per 1M tokens | Output per 1M tokens |
|---|---|---|
| Coder-Next (OpenRouter) | $0.12 | $0.75 |
| Coder-Next (Together AI) | $0.50 | $1.20 |
| Coder 480B (DashScope / qwen3-coder-plus) | $0.65 | $3.25 |
| Coder 30B (DashScope / qwen3-coder-flash) | $0.195 | $0.975 |
Coder-Next on OpenRouter is absurdly cheap: $0.12 input / $0.75 output per million tokens. For context, Claude Sonnet 4.0 runs about $3/$15 on Anthropic's API, and DeepSeek-V3 sits around $0.27/$1.10. You could run roughly 20x more Coder-Next requests than Claude for the same budget, or 2-3x more than DeepSeek.
To put it concretely: a typical agentic coding session that reads 50K input tokens and generates 10K output tokens costs about $0.01 with Coder-Next on OpenRouter. The same session with Claude Sonnet would cost roughly $0.30. Over a month of heavy daily use (say, 100 sessions), that's $1 vs $30. The trade-off is that Claude still wins on the hardest tasks — but for the 70-80% of everyday coding work, the cost savings are massive.
Alibaba's Coding Plan (Subscription Option)
If you prefer a flat monthly rate, Alibaba offers Coding Plans that bundle multiple models:
| Plan | Price | Requests/Month | First Month |
|---|---|---|---|
| Lite | $10/mo | 18,000 | $3 |
| Pro | $50/mo | 90,000 | $15 |
Both plans include access to qwen3.5-plus, qwen3-max, qwen3-coder-next, qwen3-coder-plus, kimi-k2.5, and glm-5. The Lite plan at $3 for the first month is a low-risk way to test the API models. For heavier workloads, the Pro plan works out to about $0.55 per thousand requests — reasonable for batch coding tasks.
Qwen Code: The Free CLI Agent (18K GitHub Stars)
Qwen Code is Alibaba's open-source terminal coding agent — forked from Gemini CLI and now sitting at roughly 18,000 GitHub stars. It's the glue that makes Qwen Coder models usable as a daily coding tool, and the price is hard to argue with: free.
What You Get
Qwen Code connects to the Qwen3-Coder models (defaulting to the 69.6% SWE-Bench variant) and provides a full agentic terminal experience: file read/write, shell execution, test running, multi-step planning, and sub-agent delegation. Authentication is via Qwen OAuth — no API key, no credit card required. You get free daily requests with a 256K context window.
The tool supports Skills (reusable prompt templates), SubAgents (delegated sub-tasks), and rich tool integration — meaning it can read your codebase, run your test suite, analyze failures, and apply fixes in an automated loop. Think of it as the open-source equivalent of Claude Code's agentic workflow, but powered by Qwen Coder models at zero cost.
It also works as an IDE backend. You can hook it into VS Code, Zed, or JetBrains through their respective extension protocols. And if you want to swap the underlying model — say, point it at Anthropic or OpenAI APIs — it supports that too.
Getting Started
Installation takes under two minutes. Install via npm, authenticate with your Qwen account, and you're coding:
npm install -g @anthropic-ai/qwen-codeqwen-code auth login
After authentication, just run qwen-code in any project directory. It'll pick up the codebase context automatically and start an interactive terminal session where you can describe tasks in natural language. The agent handles the rest — reading files, writing code, running commands, and iterating until the task is done.
How It Compares
| Feature | Qwen Code | Claude Code | Aider |
|---|---|---|---|
| Price | Free (Qwen OAuth) | $20/mo (Pro) or API | Free (bring your own API key) |
| Default model SWE-Bench | ~69.6% | 72-77% | Varies by model |
| GitHub stars | ~18K | ~45K | ~50K |
| Git integration | Basic | Good | Excellent |
| Sub-agents | Yes | Yes | No |
| IDE integration | VS Code, Zed, JetBrains | VS Code, JetBrains | Terminal only |
Bottom line: Claude Code leads on raw coding quality and has the more mature ecosystem. Aider has the best git integration and the largest community. Qwen Code's edge is that it's completely free with no usage caps that matter for individual developers. If you're budget-constrained or want to try agentic coding without committing $20/month, it's the obvious starting point. For the full setup guide, see our dedicated Qwen Code page.
What the Community Actually Says
We've tracked Reddit threads, developer blogs, and social media since Coder-Next launched. Here's the unfiltered picture — the praise and the problems.
What People Love
The most common sentiment on r/LocalLLaMA and developer forums: "best local coding model, period." Multiple users report that Coder-Next handles 70-80% of their everyday coding tasks at zero cost — writing functions, fixing bugs, generating tests, refactoring code. Tool calling works reliably in most scenarios, and the model recovers from errors instead of spiraling into loops — a chronic problem with older open-source coding models like CodeLlama or early DeepSeek-Coder versions.
One comment that captures the mood: "Genuinely changed what I thought was possible without paying for cloud." That tracks with the benchmarks — this is Claude Sonnet territory for routine development work, running locally on hardware most developers already own.
The cost angle keeps coming up. Developers who were paying $20-100/month for Claude or Cursor subscriptions are reporting that Coder-Next via Qwen Code or Ollama covers most of their needs at zero ongoing cost. The exceptions — truly novel architecture decisions, complex multi-file refactors across large codebases — still warrant a frontier model. But the 80% case? Covered.
What People Flag as Issues
Honest caveats from daily users:
- Random breakage in tool use — several users report the model occasionally producing malformed tool calls or breaking mid-chain, requiring manual intervention. It's not frequent, but it happens.
- Struggles with truly novel complex problems — when the task requires genuine architectural reasoning (not pattern-matching from training data), Coder-Next falls short of Claude Opus or GPT-4. Community consensus: it's great for 80% of work, but you still need a frontier model for the hardest 20%.
- No thinking mode — the lack of chain-of-thought blocks means you can't inspect the model's reasoning on tricky problems. Speed benefit, transparency cost.
- Repetitive web designs — when generating multiple web pages in sequence, outputs converge on similar minimalist layouts. Detailed prompts help, but it's a known limitation.
Sebastian Raschka (AI researcher and author) assessed Coder-Next as "roughly on par with Claude Sonnet 4.5" on SWE-Bench Pro — high praise given the compute efficiency gap. That's probably the fairest summary: it punches far above its weight class, but the weight class still matters for the hardest problems.
Frequently Asked Questions
Should I pick Coder-Next or Coder 480B?
Coder-Next for local/self-hosted use or when speed matters. It's faster, cheaper, and actually scores higher on SWE-Bench Verified (70.6% vs 67-69.6%). Pick 480B only if you're running through the DashScope API and want maximum quality on very complex tasks without worrying about cost. For most developers, Coder-Next is the better choice.
Can I use Qwen Coder in VS Code?
Yes, through multiple extensions: Continue.dev, Cline, and Twinny all support Qwen Coder models as a backend. You can either connect to a local instance (via Ollama or llama.cpp server) or point at the API. Qwen Code also has native VS Code integration.
Is Qwen Code really free?
Yes. You authenticate with Qwen OAuth (no credit card needed) and get free daily requests. There's no catch — Alibaba subsidizes API costs to drive adoption. The free tier is generous enough for individual developers; teams with high-volume needs would want the Coding Plan or self-hosted deployment.
What's the minimum hardware for Coder-Next locally?
48GB total system memory for the Q4 quantization, 57GB for Q5 (recommended). That's RAM + VRAM combined — you don't need a beefy GPU if you have enough system RAM. A 64GB desktop with any modern GPU can run it at 60+ tokens per second. Check our Can I Run Qwen? tool for your specific setup.
How does Coder-Next compare to DeepSeek for coding?
On SWE-Bench Verified, they're neck and neck: Coder-Next 70.6% vs DeepSeek-V3.2 70.2%. On SWE-Bench Pro (harder tasks), Coder-Next has a clearer lead: 44.3% vs 40.9%. The key differentiator is efficiency — Coder-Next does this with 3B active parameters, making local deployment vastly more practical. DeepSeek-V3.2 is a much larger model to run. For a broader comparison of Qwen vs DeepSeek, see our head-to-head comparison.
Where should I go from here?
If you want to explore the broader model ecosystem, start with our Qwen 3 family overview. For general-purpose tasks beyond coding, Qwen 3.5 is the current flagship. Want to try Qwen models live before committing to local setup? Our Qwen AI Chat page lets you test directly in the browser. And for detailed hardware guidance, the run locally guide and Can I Run Qwen? tool have you covered.